PinnedSerafeim Loukas, PhDForecasting Timeseries Using Machine Learning & Deep LearningIn this post, I show you how to predict stock prices using a forecasting LSTM model & a simple Ridge regression model.·11 min read·Mar 6, 2023--1--1
PinnedSerafeim Loukas, PhDinTowards AIA Movie Recommendation System in Python from ScratchIn this article, I explain simply how to build a movie recommendation system in Python!·9 min read·Apr 28, 2024--1--1
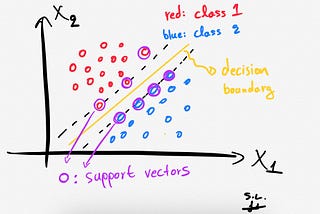
PinnedSerafeim Loukas, PhDSupport Vector Machines (SVM) clearly explained: A python tutorial for classification problems with…In this article I explain the core of the SVMs, why and how to use them. Additionally, I show how to plot the support vectors and the…·9 min read·Jul 1, 2021--1--1
PinnedSerafeim Loukas, PhDinGeek CultureK-Means Clustering: How It Works & Finding The Optimum Number Of Clusters In The DataMathematical formulation, Finding the optimum number of clusters and a working example in Python·8 min read·Jun 26, 2021--1--1
PinnedSerafeim Loukas, PhDinTowards Data ScienceClassifying Handwritten Digits Using A Multilayer Perceptron Classifier (MLP)What is a Multilayer Perceptron? What are the pros and cons of MLP? Can we classify handwritten digits accurately using a MLP classifier…·7 min read·Nov 27, 2021----
Serafeim Loukas, PhDUnveiling the ‘Data Science Hub’: Your New Destination for Expert Guidance and Bespoke Consulting…Unlock the Power of Data Science: From Custom Model Fitting to Career Advice, We’ve Got You Covered·2 min read·Jul 26, 2023----
Serafeim Loukas, PhDinTowards AIThe OpenAI Python Library & 5 Remarkable Things ChatGPT Can Do With Hands-On Examples In Python!Using the ChatGPT that everyone now knows about it via the terminal!·7 min read·Jul 21, 2023----
Serafeim Loukas, PhDHow To Master The Data Scientist Job Interview ProcessHere is my personal view based on recent experience after getting interviewed by 4 companies and finally getting 2 offers for a Data…·7 min read·Feb 15, 2023----
Serafeim Loukas, PhDinTowards AIHow To Master The Data Scientist Job Interview ProcessHere is my personal view based on my recent experience after getting interviewed by 4 companies and finally getting 2 offers for a Data…·7 min read·Feb 15, 2023--1--1
Serafeim Loukas, PhDinTowards AIHow To Use The LazyPredict Python Library To Select The Best Machine Learning Model In One LineIn this article, I introduce a nice python library, Lazy Predict. Build basic models without much code and understand which models work…·7 min read·Feb 14, 2023--3--3